
三剑客的使用
1.bash是一个命令处理器,运行在文本窗口中,并能执行用户直接输入命令
2.bash能够从文件中读取linux的命令。(脚本)
3.bash支持通配符,管道,替换,条件判断等
比较简单一点的比如
echo jjy jjy jjy
echo jjy{1..100}
mkdir jjy{1..100}.txt
#创建jjy1.txt jjy2.txt jjy3.txt jjy4.txt .......
mkdir jjy{a..z}.txt或者做一个基数的输出:
echo jjy{1..100..2}
#每两个做一个输出:jjy1 jjy3 jjy5 jjy7 jjy9 ...............别名
输入:alias可查看别名
unalias +命令 取消别名
比如可以给危险的命令rm设置一个别名
alias rm='echo 别瞎用rm'
alias #查看是否设置成功
可以使用rm进行使用查看历史命令
history
!+ 行号 #调用这行的命令
!! #调用上一次的命令linux的正则表达式
正则表达式的意义:
处理大量的字符串
处理文本
通过特殊符号的辅助,可以让linux管理员快速过滤,替换,处理所需要的祖父穿
linux三剑客
grep:文本过滤工具
sed:文本编辑器
awk:linux文本报告生成器
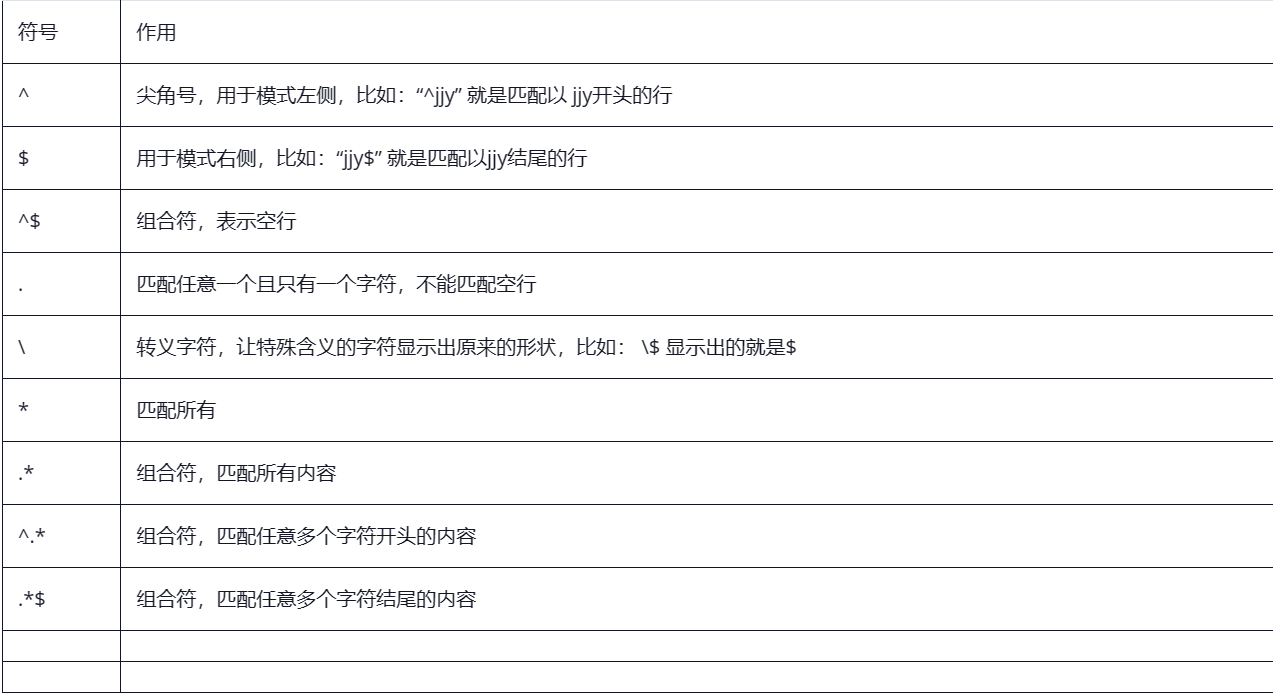
正则表达式的分类:
基本正则表达式:
^ $ . [] *
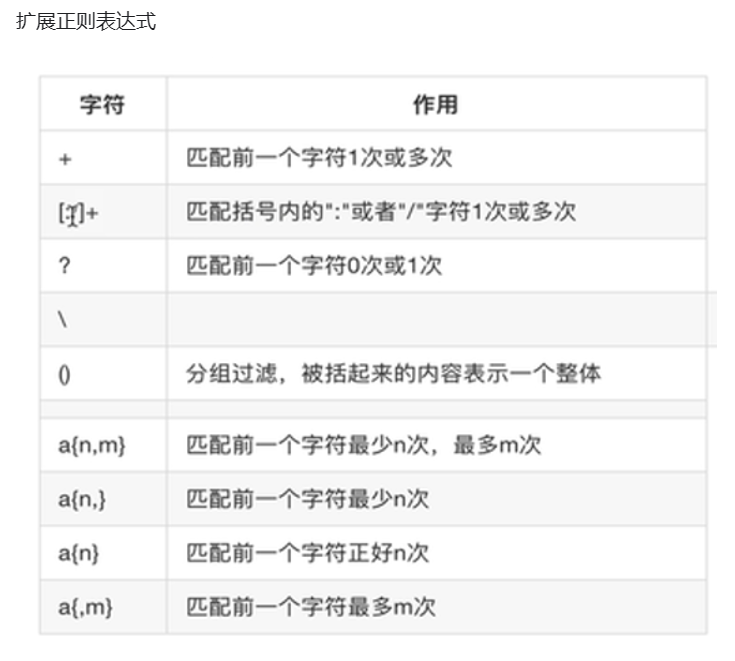
扩展正则表达式:
(){} ? |
 grep命令
grep命令
语法:grep 参数 匹配模式 文件数据
常用参数:
-i 忽略大小写
-o 仅显示匹配到的字符串本身
-v 显示不匹配的行
-E 支持使用扩展的正则表达式
-q 不输出
举例:
cat /etc/passwd > jj.txt
grep -i "root" jj.txt #过滤出含有root的行
grep -i -n "root" jj.txt #-n 可以显示行数
grep -i -n "root" jj.txt -c #-c统计多少行
grep '^$' jj.txt -n -v #-v反转参数,^$显示空行 这行命令意思:显示出了空行以外的所有内容#^的用法
grep -i -n "^root" jj.txt #过滤出以root开头的并且显示行号#$符
grep -n "\.$" jj.txt #过滤出以.结束的行并显示行号,因为.是一个表达符所以加\
grep -n "o$" jj.txt #过滤出以o结束的行并显示行号#[]符
grep -n "^[a-c]" jj.txt #过滤出以a-c开头的
grep -n "^[a-c]" jj.txt -v #不显示以a-c开头的find / -name "*.txt" | grep -E "a|c" #找出所有以txt结尾的文件 并且过滤出含有 a和c的sed命令
sed是操作,过滤和转文本内容的强大工具
-n #取消默认sed的输出,常与sed内置命令-p一起使用
-i #直接将修改结果写入文件
-e #多次编辑
-r #支持正则 案例:
案例:
cat jjy.txt
jjy qq wx
asd 111 222
qwe 333 444
zxc 555 666
777 888 999
sed -n "2,3p" jjy.txt #打印第二行和第三行的输出 p 打印 -n取消本来的内容输出
asd 111 222
qwe 333 444
sed "2,+3p" jjy.txt -n #打印第二行和第二行的后三行 +3p是打印第二行的后三行
asd 111 222
qwe 333 444
zxc 555 666
777 888 999
sed "/zxc/p" jjy.txt -n #打印出含有zxc的行(如果要打印含有什么的行用/单词/)
sed "/222/d" jjy.txt -i #将匹配到222的字符进行删除(d是删除)如果不加i就不会将文本里的删除
sed '5,10d' jjy,txt -i #删除第5行到第10行
sed 's/888/111/g' jjy.txt -i #将文件中是888的替换成111 (-i保存)
sed -e "s/jjy/my/g" -e "s/777/222/g" jjy.txt -i #-e多次编辑 将文件中jjy替换成my,777替换成222 -i保存
sed "2a jjyjjyjjy jjy" jjy.txt -i #在第二行后添加jjyjjyjjy jjy也就是第三行
sed "5i asdasdasd" jjy.txt -i #在第5行前添加asdasdasd并保存
sed "3i jjyjjyjjy \nzzzzzzz" jjy.txt -i #在第三行前添加两行一行是jjy… 一行是zzzzz \n后面不用空格
sed "a -----------" jjy.txt -i #a是每一行(在每一行后面添加--------------)#案例
ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.11.11 netmask 255.255.255.0 broadcast 192.168.11.255
inet6 fe80::20c:29ff:fec4:4fdd prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:c4:4f:dd txqueuelen 1000 (Ethernet)
RX packets 375690 bytes 559051502 (533.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 17436 bytes 1904142 (1.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#如果只要取出ip192.168.11.11使用:
ifconfig eth0 | sed "2p" -n | sed "s/^.*inet//" | sed "s/net.*$//"
# "s/^.*inet//" 是将init之前不管多少字符都替换成//(空)
# "s/net.*$//" 是将net后不管多少字符替换成//(空)awk命令
#awk的语法
#awk [可选参数] ‘模式 {动作}‘ 文件
#动作一般是:print和printf
cat 123.txt
jjy qq wx
asd 111 222
qwe 333 444
zxc 555 666
777 888 999
awk '{print $1}' 123.txt #打印第一行
awk '{print $1,$2}' 123.txt #打印第一行和第二行
#awk默认以空格为分隔符,多个空格也识别为一个空格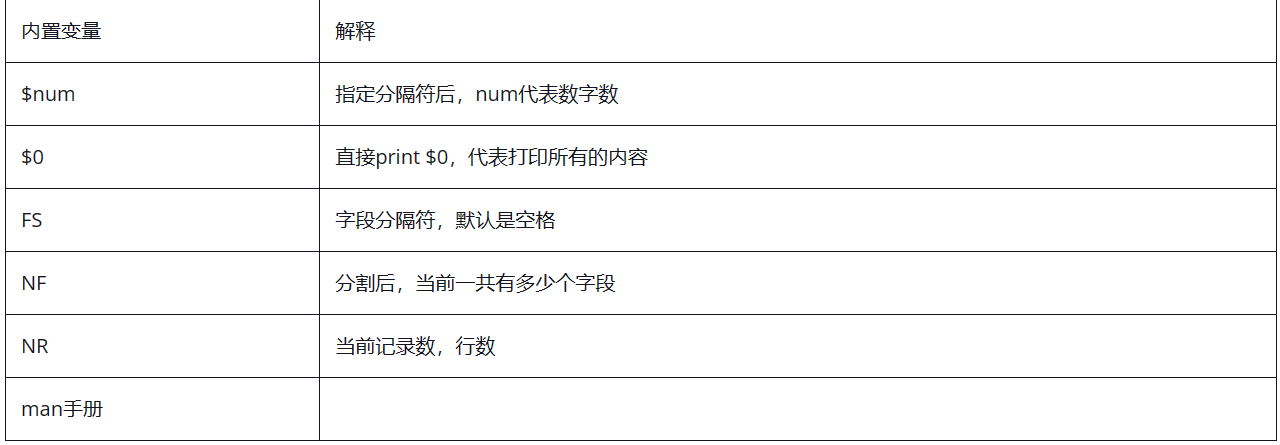 1
1
awk '{print "第一列:"$1,"第二列:"$2}' 123.txt
#打印第一行和第二行并且在前面加 第一列 第二列,添加相应的内容需要 ”“#NR在awk中表示行号,NR==5就表示行号是5的那一行
#一个=是修改变量值的意思,两个=是关系运算符,就是等于的意思
awk 'NR==5{print $0}' 123.txt
#使用awk输出123.txt,然后找到第5行的内容(NR==5就是找到第5行),并且打印他的所有
awk 'NR==3,NR==5{print $0}' 123.txt
#打印第三行到第5行
组合使用:
cat 123.txt
jjy qq wx
asd 111 222
qwe 333 444
zxc 555 666
777 888 999
awk 'NR==2{print "我是第二行的第三列:"$3}' 123.txt
输出:我是第二行的第三列:222
#意思:NR==2(显示第二行) "我是第二行的第三列:" 自定义的字,$3第三列
awk 'NR==3,NR==5{print NR,$0}' 123.txt
#其中 NR就是会显示行号
NF显示有多少字节
awk '{print $1,NF}' 123.txt
jjy 3
asd 3
qwe 3
zxc 3
777 3
#意思就是打印第一行并且显示一共有多少字段
awk '{print $(NF-1)}' 123.txt
#打印倒数第二列,$(NF-1)NF代表字节数 -1就是倒数第二列 -0就是倒数第一列
awk '{print $(NF-1),$(NF-0)}' 123.txt
#打印出倒数第一列和倒数第二列